- احتمالا اتریوم به زودی به این سطح کلیدی کاهش می یابد
- Defiance Quantum ETF (QTUM)
- Global Times: ایجاد جامعه ای با آینده مشترک برای راه بشر به صلح ، توسعه و سعادت
- متنوع سازی نمونه کارها: چیست و چرا مهم است؟
- کد خطا 12: معامله نامعتبر
- استراتژی های ساده
- هزینه متوسط هزینه سرمایه (WACC)
- قیمت سهم هند Vix
- 2023-2030 اندازه بازار تیغه برش عمیق با تولیدات و فرصت های آینده
- آموزش به عنوان معامله گر

آخرین مطالب
امکانات وب


یک پیاده روی تصادفی از طریق تحقیقات علوم کامپیوتر ، توسط آدریان کلیر با خوشحالی سریع انجام داد
یافتن الگوهای غافلگیرکننده در یک پایگاه داده سری زمانی در زمان و مکان خطی
در مقاله گوریل فیس بوک ، نویسندگان به تعدادی از تکنیک های تحلیل سری زمانی اضافی که می خواهند به مرور زمان به سیستم اضافه کنند ، اشاره کردند. مقاله امروز یکی از آنهاست و به این سؤال می پردازد که چگونه می توان الگوهای شگفت آور یا غیر عادی را در یک مجموعه داده سری زمانی پیدا کرد.
توجه داشته باشید که این مشکل نباید با مشکل نسبتاً ساده تشخیص دور از ذهن اشتباه گرفته شود. تعریف کلاسیک هاوکینز از یک چیز مهم "... مشاهده ای است که آنقدر از مشاهدات دیگر منحرف می شود و این ظن را ایجاد می کند که از یک مکانیسم متفاوت تولید شده است."با این حال ، ما علاقه ای به یافتن داده های غافلگیرکننده به صورت جداگانه نداریم ، ما در یافتن الگوهای غافلگیرکننده ، یعنی ترکیبی از نقاط داده که ساختار و فرکانس آنها به نوعی از انتظارات ما سرپیچی می کند ، جالب هستیم.
با توجه به برخی از داده های قبلاً دیده شده ، یک الگوی به عنوان تعجب آور تعریف می شود اگر فرکانس وقوع آن متفاوت از آنچه انتظار می رود به طور اتفاقی متفاوت باشد. بنابراین نیازی نیست که به نوعی مشخص کنیم که چه چیزی را جستجو کنید که ممکن است تعجب آور باشد. تنها پیش نیاز در دسترس بودن داده ها به عنوان عادی (غیر غافلگیرکننده) است.
یک الگوی سری زمانی P ، استخراج شده از پایگاه داده X نسبت به یک پایگاه داده R تعجب آور است ، اگر فرکانس وقوع آن با آنچه انتظار می رود به طور اتفاقی متفاوت باشد ، با فرض اینکه R و X با همان فرآیند اساسی ایجاد می شوند.
مراحل سطح بالا الگوریتم تارزان به شرح زیر است:
- ابتدا سری زمانی ورودی X را به یک سری زمانی گسسته شده در برخی از مجموعه های اندازه ثابت از نشانه های A (الفبای) تبدیل کنید.(این بعداً به ما این امکان را می دهد تا احتمال وقوع یک وقوع را محاسبه کنیم و از پارادوکس جلوگیری کنیم که احتمال یک عدد واقعی خاص که از هر توزیع انتخاب می شود صفر است).
- همان کار را با سری زمانی مرجع انجام دهید
- درختان پسوند را برای سری زمانی گسسته X و R ایجاد کنید و از یک مدل مارکوف استفاده کنید تا مشخص شود که بسترهای موجود در گره های موجود در درخت پسوند X چقدر است.
- یک پنجره کشویی را روی سری زمانی گسسته شده برای X حرکت دهید و با استفاده از نمرات از پیش محاسبه شده در مرحله قبل ، نمره غافلگیرکننده را برای هر پنجره جستجو کنید.
- پرچم را به عنوان هر پنجره با نمره بر روی آستانه شگفت آور کنید.

ما به جزئیات مربوط به گسسته کردن سری زمانی ، محاسبه درختان پسوند و تعیین احتمال به زودی خواهیم پرداخت.
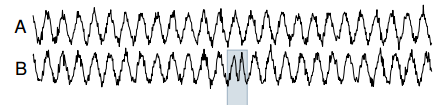
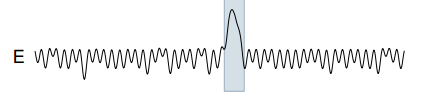
به عنوان نمونه ای از تارزان در محل کار ، یک موج سینوسی پر سر و صدا را به عنوان سری زمانی مرجع (A در تصویر زیر) در نظر بگیرید ، و یک ناهنجاری مصنوعی که به عنوان یک آزمایش معرفی می شود (B در تصویر زیر - که در آن دوره سری زمانی استبه طور موقت نصف شده). تارزان برای مدت زمان آنامولی (E) اوج "عالی" را نشان می دهد.
تارزان همچنین برای یک مرکز تحقیقاتی هلندی در یک مجموعه داده تقاضای قدرت دنیای واقعی مورد آزمایش قرار گرفت. الگوی مرجع قله های محکمی را برای روزهای هفته نشان می دهد و به دنبال آن آخر هفته های نسبتاً ساکت:

سه هفته تعجب آور در مجموعه داده ها همانطور که توسط تارزان یافت می شود در زیر نشان داده شده است:
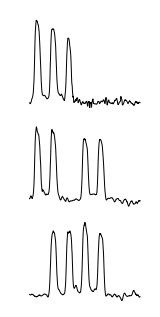
تارزان سه سکانس را که مربوط به هفته های حاوی تعطیلات ملی در هلند است ، برگرداند. به طور خاص ، از بالا به پایین ، هفته ای که در تاریخ 25 و 26 دسامبر و هفته های حاوی چهارشنبه 30 آوریل (Koninginnedag ، "روز ملکه") و 19 مه (ویت دوشنبه) قرار دارد.
هنگامی که با داده های واقعاً تصادفی آزمایش شد ، پس از دیدن کافی ، تارزان هر "الگوی" را کمتر و کمتر تعجب آور دانست (یعنی تارزان شگفتی های مثبت کاذب ایجاد نمی کند).
بیایید به درک کاملی از نحوه کار تارزان بپردازیم.
سریال های زمانی گسسته
برای محاسبه این اندازه گیری (تعجب) ، باید احتمال وقوع الگوی علاقه را محاسبه کنیم. در اینجا با پارادوکس آشنا روبرو می شویم که احتمال انتخاب یک عدد واقعی خاص از هر توزیع صفر است. از آنجا که یک سری زمانی یک لیست سفارش داده شده از اعداد واقعی است که پارادوکس به وضوح اعمال می شود. راه حل بارز این مشکل ، تفکیک سری زمانی در برخی الفبای محدود σ است. استفاده از الفبای محدود به ما این امکان را می دهد تا از مدل های مارکوف استفاده کنیم تا احتمال پیش بینی شده از یک الگوی قبلاً غیب را تخمین بزنیم.
آنچه ما می خواهیم به پایان برسیم ، یک رشته (دنباله سفارش داده شده) از نمادها از الفبای σ است. اگر یک رشته X را می توان در توالی UVW تجزیه کرد که در آن U ، V و W بستر (یا کلمات) X هستند ، سپس U پیشوند X نامیده می شود و W به عنوان پسوند نامیده می شود. یک رشته y در موقعیت I از متن x وجود دارد اگر بستر x از موقعیت I ، از طول | شروع کند |y | ، برابر y است. نویسندگان از f استفاده می کنندx(y) برای نشان دادن تعداد وقایع y در x.
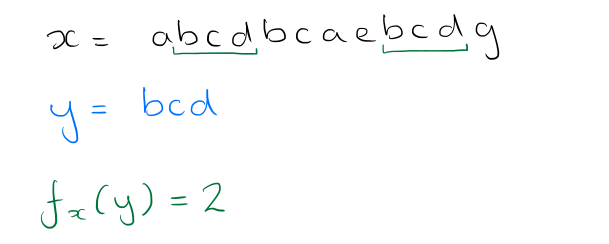
برای گسسته کردن جریان ، اندازه الفبای و طول پنجره ویژگی را انتخاب کنید. پنجره ویژگی را در طول سری زمانی بکشید و در هر مرحله داده های موجود در پنجره را بررسی کرده و یک عدد واقعی را از آن محاسبه کنید. این شماره واقعی باید محاسبه شود تا برخی از ویژگی های داده ها را نشان دهد (می توانید از هر عملکردی که در دامنه شما معنی دارد استفاده کنید ، در مقاله ، نویسندگان از شیب بهترین خط استفاده می کنند).
تمام نمرات محاسبه شده را بگیرید و آنها را مرتب کنید. بر اساس این لیست مرتب شده ، سطل اندازه الفبای را به گونه ای مشتق کنید که تعداد مساوی از نمرات در هر سطل قرار می گیرد. حالا به دنباله نمرات برگردید و هر نمره را بر اساس تعداد سطلی که در آن قرار دارد جایگزین کنید. کل فرآیند در زیر نشان داده شده است:
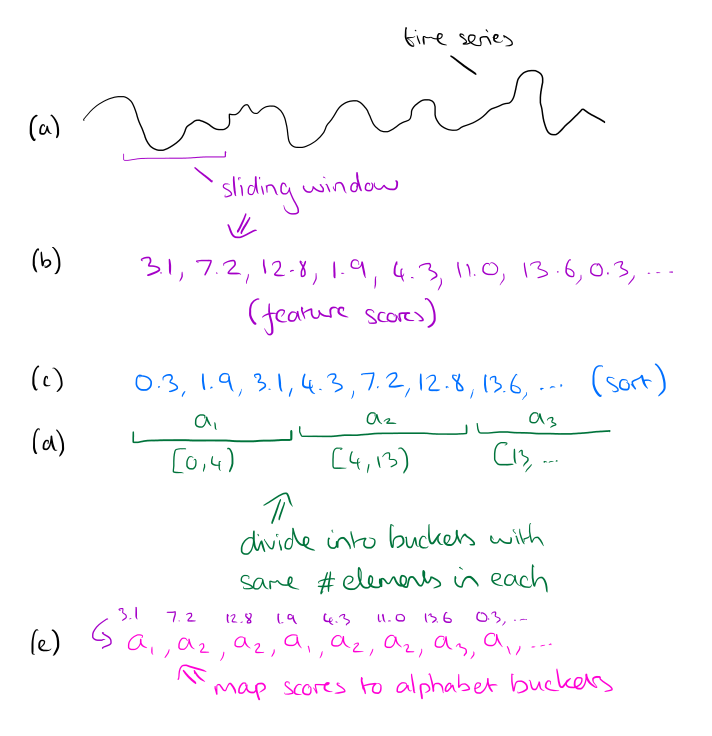
برای بانکهای اطلاعاتی بزرگ ، مرزهای ویژگی بسیار پایدار خواهد بود ، بنابراین به جای مرتب سازی کل مجموعه داده می توان یک نمونه را تهیه و سطل ها را بر اساس آن محاسبه کرد. اگر نمونه از اندازه √ | r |سپس الگوریتم استخراج ویژگی O (R) است.
ساختن یک درخت پسوند
یک ساختار کارآمد فضایی برای شمارش تعداد وقایع هر بستر در یک دنباله ، یک درخت پسوند است.(ما به این موارد نیاز داریم تا بفهمیم آنها در مرحله بعدی الگوریتم تارزان چقدر تعجب آور هستند ...).
برای یک رشته طول n ، یک درخت پسوند دارای برگهای N است که دارای شماره 1 تا n هستند و به دنبال یک مسیر از طریق درخت از ریشه به شماره برگ ، پسوند من در فهرست I در رشته شروع می شود. درک ساخت و ساز با معکوس کردن رشته و ساختن درخت از آنجا مانند طرح زیر ساده ترین است. اما چندین ساختار هوشمندانه با O (n log | σ |) و همچنین الگوریتم های خطی روی خط (یعنی ، در حال انجام شخصیت توسط شخصیت از طریق رشته از اول تا آخر) در دسترس است.
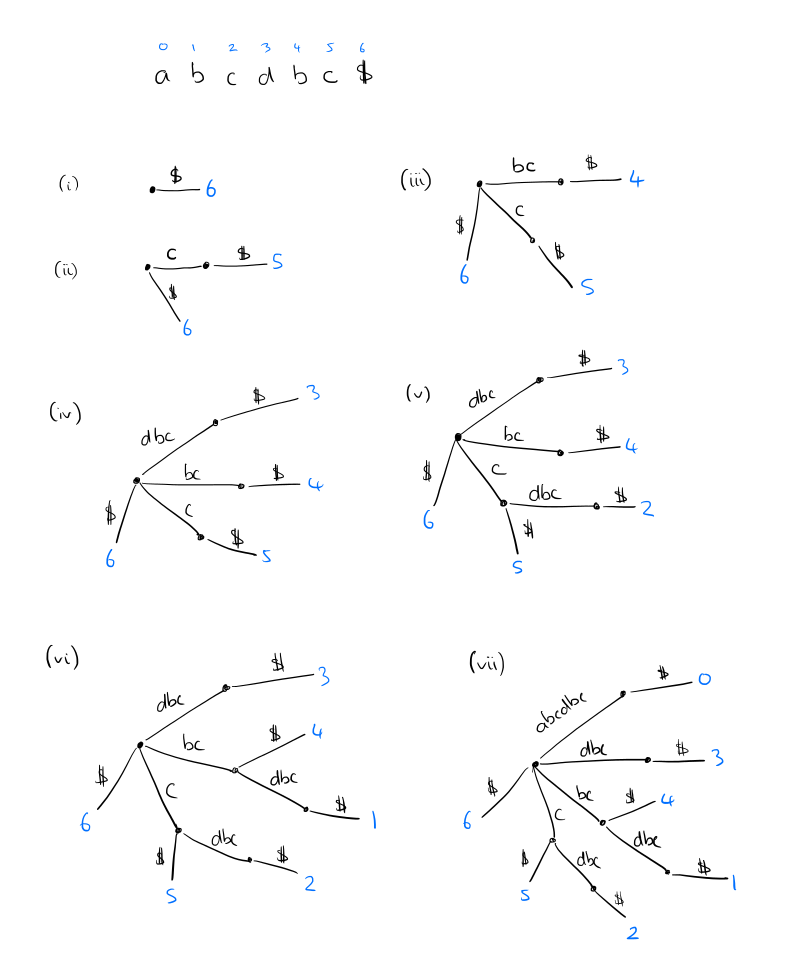
کل درخت را می توان با نگه داشتن نشانگرهای شاخص به وقایع برچسب ها در متن به جای ذخیره خود برچسب ها در فضای خطی ذخیره کرد.
با ساختن درخت ، برخی از پردازش های اضافی امکان شمارش و یافتن تمام نمونه های متمایز از هر الگوی در زمان O (M) را فراهم می کند ، جایی که M طول الگوی است ...
فرض کنید ما می خواهیم همه موارد یک کلمه w را پیدا کنیم و شمارش کنیم (به عنوان مثال "قبل از میلاد" در مثال بالا). گره Locus __ __ را در درختی که نمایانگر W است ، یا کوتاهترین پسوند W را پیدا کنید اگر W در وسط یک قوس به پایان برسد. تعداد وقایع fx(w) با تعداد برگهای موجود در زیر درخت ریشه در __ داده می شود.
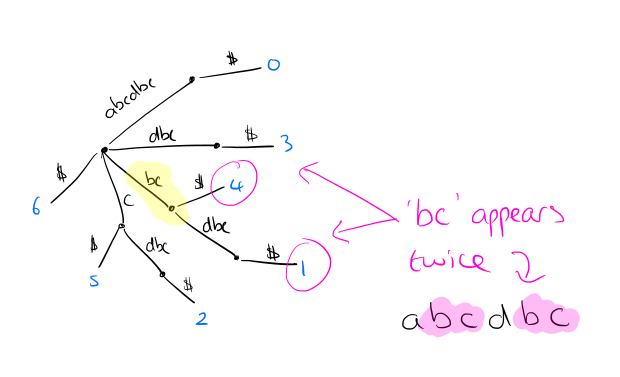
ما می توانیم درخت را پردازش کنیم و در هر گره داخلی تعداد برگهای زیر آن را ذخیره کنیم و باعث می شود فرکانس بعدی سریع جستجو شود.
محاسبه احتمال با مدل های مارکوف
در نظر بگیرید که یک رشته توسط یک زنجیره ثابت مارکوف از سفارش M ≥ 1 در الفبای محدود σ ایجاد می شود. اگر x = x[1],x[2],…x[n]مشاهده روند تصادفی و y = y است[1],y[2],…y[م]یک الگوی دلخواه اما ثابت بیش از σ با m است
(به طور غیررسمی ، با توجه به دنباله ای که تاکنون دیده شده است ، احتمال شخصیت بعدی C چیست).
ما مدل مارکوف واقعی را که البته رشته را تولید می کند ، نمی دانیم ، اما می توانیم آن را از یک دنباله مشاهده شده X تخمین بزنیم. به طور خاص ، احتمال انتقال را می توان با حداکثر برآوردگر احتمال تخمین زد:
به عنوان مثال ، با توجه به رشته "abcabcabd" ، ما می خواهیم احتمال انتقال را برای (‘ab" ، c) بدانیم. این تعداد وقایع "ABC" (2) است که بر اساس تعداد وقایع "AB" (3) تقسیم می شود - بنابراین ما آن را 2/3 تخمین می زنیم.
احتمال ثابت توسط _f تخمین زده می شودx(y[1 ، م]) / (n - m + 1). بازگشت به مثال "abcabcadb" ، احتمال ثابت "ABC" 2 / (9 - 3 + 1) = 2/7 است.
تعداد فرکانس مورد نیاز برای برآورد این احتمالات به راحتی در درختان پسوند رمزگذاری می شود. اکنون ما آماده هستیم تا احتمال دیدن رشته هایی را که در X مشاهده می کنیم ، در مقایسه با سری مرجع R.
بگذارید فاکتور مقیاس α = (| x | - m + 1) / (| r | - m + 1) (یعنی اندازه های نسبی توالی های x و r).
با توجه به یک درخت پسوند tr,ساخته شده برای سری مرجع سری R ، و یک درخت پسوند tساخته شده از سری زمانی مشاهده شده X ، یک سفر وسعت اول T را انجام دهیدxبررسی هر گره U در txبه نوبه خود.
- رشته W را که با عبور از t تشکیل شده است محاسبه کنیدxاز ریشه به گره U.
- جستجو در Tr.
- اگر W در T وجود داشته باشدrسپس بگذارید تعداد مورد انتظار وقایع W در x αF باشدr(W) (یعنی شماری که در آن گره در T ذخیره کردیمrدر طول پیش پردازش ، مقیاس شده توسط فاکتور α)
- اگر W در T وجود نداردrسپس بزرگترین L را پیدا کنید به گونه ای که تمام بسترهای طول L در W وجود داردrبشرتعداد مورد انتظار وقایع W را در x تنظیم کنید
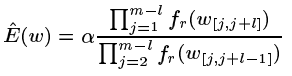
(مقاله کامل برای مشتق این فرمول را ببینید)
- اگر هیچ L مناسب وجود ندارد ، تعداد مورد انتظار وقایع W را در x بر اساس احتمال نمادها از t تنظیم کنیدr
- نمره غافلگیرکننده را تفاوت بین تعداد مشاهده شده وقایع و تعداد مورد انتظار وقایع قرار دهید.
در اینجا الگوریتم پیش پردازش کامل وجود دارد:

ما را در سایت تجارت با گزینههای باینری دنبال می کنید
برچسب :
نویسنده : حمیدرضا پگاه
بازدید : 27
