- احتمالا اتریوم به زودی به این سطح کلیدی کاهش می یابد
- Defiance Quantum ETF (QTUM)
- Global Times: ایجاد جامعه ای با آینده مشترک برای راه بشر به صلح ، توسعه و سعادت
- متنوع سازی نمونه کارها: چیست و چرا مهم است؟
- کد خطا 12: معامله نامعتبر
- استراتژی های ساده
- هزینه متوسط هزینه سرمایه (WACC)
- قیمت سهم هند Vix
- 2023-2030 اندازه بازار تیغه برش عمیق با تولیدات و فرصت های آینده
- آموزش به عنوان معامله گر

آخرین مطالب
امکانات وب


در این صفحه ضرایب همبستگی تتراکوری و پلیچوری ، معنی و کاربردهای آنها را توضیح می دهد ، نمونه ها و منابع را ارائه می دهد ، برنامه هایی را برای تخمین آنها ارائه می دهد و در مورد سایر نرم افزارهای موجود بحث می کند. در حالی که بحث در درجه اول به مشکلات توافق نامه متعهد است ، اما به اندازه کافی کلی است که در مورد سایر کاربردهای این آمار اعمال شود.
توضیحی واضح و مختصر از ضرایب همبستگی تتراکوری و پلیچوری ، از جمله موضوعات مربوط به تخمین آنها ، در دراسو (1988) یافت می شود. اولسون (1979) نیز مفید است.
آنچه بحث حاضر را متمایز می کند ، این دیدگاه است که مدل های همبستگی تتراکوری و پلیچوری موارد خاصی از مدل سازی صفت نهفته هستند.(این یک مشاهده جدید نیست ، اما گاهی اوقات نادیده گرفته می شود). شناخت این امر امکانات مهم جدید را باز می کند. به طور خاص ، این امکان را به فرد می دهد تا فرضیات توزیع را که محدودترین ویژگی مدل های همبستگی تتراچوری و پلیچوری "کلاسیک" است ، آرامش بخشد.
در هر صورت توجه داشته باشید که اصطلاحات همبستگی تتراکوری و همبستگی پلی چوریک منسوخ شده و به طور قابل ملاحظه ای نادرست هستند. آنها به سری تتراکوریک و سری پلی چوریک ، روشهای عددی که قبلاً (قبل از رایانه های مدرن) برای تسهیل محاسبات استفاده می شدند ، اشاره می کنند. اکنون این همبستگی ها با حداکثر احتمال یا وسایل دیگر تخمین زده می شود. از این رو اصطلاحی مانند همبستگی نهفته (یا همبستگی مداوم نهفته) مناسب تر است.
خلاصه
همبستگی تتراکوری (پیرسون ، 1901) ، برای داده های باینری ، و همبستگی پلی چوریک ، برای داده های مرتب شده ، روشهای عالی برای اندازه گیری توافق نامه Rater است. آنها تخمین می زنند که اگر رتبه بندی در مقیاس مداوم انجام شود ، ارتباط بین رأی دهندگان چه خواهد بود. از نظر تئوری ، آنها نسبت به تغییر در تعداد یا "عرض" دسته های رتبه بندی متغیر هستند. همبستگی های تتراکوری و پلی چوریک همچنین چارچوبی را فراهم می کند که امکان آزمایش همگن حاشیه ای بین رأی دهندگان را فراهم می کند. بنابراین ، این آمار اجازه می دهد تا به طور جداگانه هر دو مؤلفه توافق نامه را ارزیابی کنند: توافق در مورد تعریف صفت و توافق در مورد تعاریف دسته های خاص.
این آمار فرضیات خاصی را انجام می دهد. با همبستگی پلیچوری ، فرضیات قابل آزمایش هستند. در صورت وجود تنها دو رأی دهنده ، این فرضیات با همبستگی تتراکوری قابل آزمایش نیستند. با این حال ، در برخی از برنامه ها ، ملاحظات نظری ممکن است استفاده از همبستگی تتراکوری را بدون آزمایش تناسب مدل توجیه کند.
جوانب مثبت و منفی: ضرایب همبستگی تتراکوری و پلیچوری
- فرضیات مدل همیشه مناسب نیستند-به عنوان مثال ، اگر ویژگی نهفته واقعاً گسسته باشد.
- فقط برای دو رأی دهنده ، هیچ راهی برای آزمایش فرضیات همبستگی تتراکوری وجود ندارد.
توضیح شهودی
نمونه ای از دو روانپزشک (رأی دهندگان 1 و 2) را در نظر بگیرید که برای حضور/عدم وجود افسردگی عمده تشخیص داده می شود. اگرچه تشخیص دوگانگی است ، ما اجازه می دهیم که افسردگی به عنوان یک صفت به طور مداوم در جمعیت توزیع شود.
شکل 1 (پیش نویس). متغیر مداوم نهفته (شدت افسردگی ، Y) ؛و آستانه گسسته کننده (T).
در تشخیص یک مورد معین ، یک رأی سطح افسردگی پرونده ، Y ، نسبت به برخی از آستانه ها را در نظر می گیرد ، t: اگر سطح داوری بالاتر از آستانه باشد ، تشخیص مثبت انجام می شود. در غیر این صورت تشخیص منفی است.
شکل 2 وضعیت دو رأی دهنده را به تصویر می کشد. این توزیع موارد را از نظر سطح افسردگی نشان می دهد که توسط Rater 1 و Rater 2 مورد قضاوت قرار می گیرد.
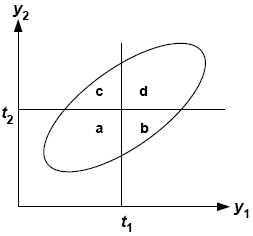
شکل 2. توزیع مشترک (بیضی) از شدت افسردگی که توسط دو رأی دهنده داوری می شود (Y1 و Y2). و آستانه های گسسته کننده (T1 AN T2)
A ، B ، C و D نسبت مواردی را که در هر منطقه تعریف شده توسط آستانه دو رأی دهنده مشخص می شود ، نشان می دهد. به عنوان مثال ، A نسبت زیر هر دو آستانه رأی دهندگان است و بنابراین توسط هر دو منفی تشخیص داده می شود.
این نسبت ها با خلاصه ای از داده ها به عنوان طبقه بندی متقاطع 2 x 2 از رتبه بندی رأی دهندگان مطابقت دارد.
شکل 3 (پیش نویس). نسبت های متقاطع برای رتبه بندی باینری توسط دو رأی دهنده.
باز هم ، A ، B ، C و D در شکل 3 نشان دهنده نسبت ها (نه فرکانس) است.
هنگامی که ما نسبت به طبقه بندی متقاطع مشاهده شده A ، B ، C و D را برای یک مطالعه می دانیم ، تخمین مدل ارائه شده توسط شکل 2 یک موضوع ساده استپارامتر سوم ، Rho ، که "چربی" بیضی را تعیین می کند. Rho همبستگی تتراکوری یا R*است. این می تواند در اینجا به عنوان همبستگی بین شدت بیماری داوری (قبل از استفاده از آستانه ها) تعبیر شود که توسط Rater 1 و Rater 2 مشاهده می شود.
اصل تخمین ساده است: اساساً ، یک برنامه رایانه ای ترکیبات مختلفی را برای T1 ، T2 و R* امتحان می کند تا مقادیر پیدا شود که نسبت های مورد انتظار برای A ، B ، C و D در شکل 2 تا حد امکان به مشاهده نزدیک باشدنسبت در شکل 3. مقادیر پارامتر که این کار را انجام می دهند به عنوان (برآورد) مقادیر واقعی و جمعیت در نظر گرفته می شوند.
همبستگی پلیچوری ، که در هنگام وجود بیش از دو سطح رتبه بندی سفارش داده شده استفاده می شود ، یک گسترش ساده از مدل فوق است. تفاوت این است که آستانه های بیشتری وجود دارد ، مناطق بیشتری در شکل 2 و سلولهای بیشتری در شکل 3 وجود دارد.
توصیف همراه با جزئیات
معرفی
در بسیاری از مواقع ، حتی اگر یک صفت ممکن است مداوم باشد ، ممکن است تقسیم آن به سطح مرتب شده راحت باشد. به عنوان مثال ، برای اهداف تحقیقاتی ، ممکن است سطح درد سردرد را در دسته های هیچ ، خفیف ، متوسط و شدید طبقه بندی کند. حتی برای ویژگی هایی که معمولاً به عنوان گسسته تلقی می شود ، هنوز هم ممکن است درجه بندی های مداوم را در نظر بگیرد-به عنوان مثال ، افراد آلوده به ویروس آنفولانزا سطح مختلفی از شدت علائم را نشان می دهند.
ضرایب همبستگی تتراکوری و همبستگی پلیچوری مناسب است که ویژگی نهفته که اساس رتبه بندی را تشکیل می دهد ، می تواند به عنوان مداوم تلقی شود. ما در اینجا مدل اندازه گیری و فرضیات مربوط به همبستگی تتراکوری را بیان خواهیم کرد. مدل و فرضیات مربوط به همبستگی پلی چوریک یکسان است-تنها تفاوت این است که پارامترهای آستانه بیشتری برای همبستگی های پلی چوریک وجود دارد ، که مربوط به تعداد رتبه بندی مرتب شده بیشتر است.
مدل اندازه گیری
ما با برخی از نمادها و تعاریف شروع می کنیم. اجازه دهید:
X1 و X2 رتبه بندی مانیفست (مشاهده شده) توسط رأی دهندگان (یا روشها ، تست های تشخیصی و غیره) 1 و 2 است. اینها متغیرهای دارای ارزش گسسته هستند.
y1 ، y2 متغیرهای مداوم نهفته مرتبط با x1 و x2 است. اینها "برداشتهای" از قبل تخریب شده و مداوم از سطح صفت است ، همانطور که توسط رأی دهندگان 1 و 2 قضاوت می شود.
رتبه بندی یا تشخیص یک مورد با سطح صفت واقعی مورد ، T. شروع می شود. به تصور هر یک از سطح ویژگی های پرونده (Y1 و Y2). هر یک از آستانه های گسسته کننده را برای این سطح صفت داوری اعمال می کند تا یک رتبه بندی دوگانگی یا مرتب شده (X1 و X2) به دست آورد.
-
- y1 = bt + u1 + e1 ، y2 = bt + u2 + e2 ،
همبستگی تتراکوری فرض می کند که ویژگی نهفته T به طور معمول توزیع می شود. از آنجا که مقیاس بندی دلخواه است ، ما آن را مشخص می کنیم~n (0 ، 1). به طور مشابه خطا فرض می شود که به طور عادی توزیع می شود (و هم بین رأی دهندگان و هم در مورد موارد مستقل). به دلایلی که لازم نیست در اینجا دنبال کنیم ، این مدل با فرض اینکه VAR (E1) = VAR (E2) کلی بودن را از دست نمی دهد. بنابراین ما تصریح می کنیم که e1 ، e2~N (0 ، سیگماe). نتیجه این فرضیات این است که Y1 و Y2 نیز باید به طور عادی توزیع شوند. برای رفع مقیاس ، ما مشخص می کنیم که var (y1) = var (y2) = 1. نتیجه می گیرد که b1 = b2 = b = همبستگی هر دو y1 و y2 با صفت نهفته.
-
- Y1 = B1T + E1 ، Y2 = B2T + E2.
یک "نمودار مسیر" ساده ممکن است این موضوع را روشن کند:
شکل 4 (پیش نویس). نمودار مسیر.
در اینجا b ضریب مسیر است که نشان دهنده تأثیر T در Y1 و Y2 است. کسانی که با قوانین تجزیه و تحلیل مسیر آشنا هستند ، می بینند که همبستگی Y1 و Y2 صرفاً محصول درجه وابستگی آنها به T است-این B 2 است.
گذشته از این ، ممکن است در نظر داشته باشد که ارزش B به خودی خود جالب است ، از آنجا که اندازه گیری از ارتباط رتبه بندی ها با ویژگی نهفته واقعی-یعنی ، اندازه گیری اعتبار یا صحت رتبه بندی را ارائه می دهد.
همبستگی تتراکوری R* به راحتی قابل تفسیر به عنوان معیار ارتباط بین رتبه بندی Rater 1 و Rater 2 است. از آنجا(1) تعداد سطح رتبه بندی ، یا (2) نسبت های حاشیه ای برای سطح رتبه بندی (به عنوان مثال ، نرخ پایه.) این واقعیت که این ارتباط به شکل آشنای یک همبستگی بیان شده است نیز مفید است.
فرضیات 1 --4 می تواند به عنوان این فرضیه بیان شود که Y1 و Y2 از توزیع عادی دو متغیره پیروی می کنند.
فرض خواهیم کرد که یکی از درک نظری کافی از برنامه برای پذیرش فرض استمرار نهفته است.
فرض دوم-که از توزیع عادی برای T-به طور بالقوه سوال برانگیز است. با این حال ، عادی بودن مطلق احتمالاً لازم نیست. یک توزیع غیرمعمول ، تقریباً متقارن ممکن است به اندازه کافی نزدیک باشد. همچنین ، این مدل به طور ضمنی امکان تحول یکنواخت از متغیرهای مداوم نهفته را فراهم می کند. یعنی یک روش دقیق تر برای بیان فرضیات 1-4 این است که می توان با برخی از تحولات یکنواخت Y1 و Y2 توزیع عادی دو متغیره را بدست آورد.
فرضیات مدل را می توان برای همبستگی پلی چوریک آزمایش کرد. این کار با مقایسه تعداد مشاهده شده موارد برای هر ترکیبی از سطح رتبه بندی با موارد پیش بینی شده توسط مدل انجام می شود. این کار با تست مربع مربع با نسبت احتمال ، G 2 (Bishop ، Fienberg & Holland ، 1975) انجام می شود ، که مشابه آزمایش معمول Chi-Square Pearson است (برای اطلاعات بیشتر در مورد آزمایش Chi-Square Pearson نیز می توان استفاده کرد. این تست ها ، متداول را برای تست مدل متناسب با وب سایت تجزیه و تحلیل کلاس نهفته مشاهده کنید.
-
- r* = b 2
- صفتی که بر اساس آن رتبه بندی می شود مداوم است.
- ویژگی نهفته به طور معمول توزیع می شود.
- خطاهای رتبه بندی به طور معمول توزیع می شوند.
- var (e) در سطح T. همگن است.
- خطاها بین رأی دهندگان مستقل هستند.
- خطاها بین موارد مستقل هستند.
برای همبستگی تتراکوری r = c = 2 ، و هیچ DF برای آزمایش مدل وجود ندارد. هرچند که بیش از دو رأی دهنده وجود دارد ، می توان مدل را آزمایش کرد.
با استفاده از همبستگی پلیچوری برای اندازه گیری توافق
در اینجا مراحلی که ممکن است برای استفاده از همبستگی تتراکوری یا پلیچوری برای ارزیابی توافق در یک مطالعه انجام شود. برای راحتی ، ما عمدتاً به همبستگی پلی چوریک اشاره خواهیم کرد ، که شامل همبستگی تتراکوریک به عنوان یک مورد خاص است.
1. مقدار همبستگی پلیچوری را محاسبه کنید.
برای این یک برنامه رایانه ای ، مانند برنامه های شرح داده شده در بخش نرم افزار ، مورد نیاز است.
2. ارزیابی مدل را ارزیابی کنید.
مرحله بعدی تعیین اینکه آیا فرضیات همبستگی پلی چوریک از نظر تجربی معتبر هستند یا خیر. این کار با آزمایش خوب و مناسب انجام می شود که فرکانسهای متقاطع مشاهده شده را با فرکانسهای پیش بینی شده مدل مقایسه می کند که قبلاً شرح داده شده است. همانطور که اشاره شد ، این آزمایش برای همبستگی تتراکوری قابل انجام نیست.
PRELIS شامل آزمایش متناسب با مدل در هنگام برآورد همبستگی پلی چوریک است. مشخص نیست که آیا SAS Proc Freq چنین آزمایشی را شامل می شود.
3. میزان و اهمیت همبستگی را ارزیابی کنید.
با فرض اینکه تناسب مدل قابل قبول است ، قدم بعدی توجه به بزرگی همبستگی پلی چوریک است. ارزش آن به همان روش همبستگی پیرسون تفسیر می شود. با نزدیک شدن به ارزش 1. 0 ، توافق بیشتر در مورد تعریف صفت نشان داده شده است. مقادیر نزدیک 0 نشان دهنده توافق کمی در مورد تعریف صفت است.
ممکن است فرد بخواهد فرضیه تهی از هیچ ارتباطی بین رأی دهندگان را آزمایش کند. حداقل دو راه برای انجام این کار وجود دارد. اولین استفاده از خطای استاندارد تخمین زده شده از همبستگی پلی چوریک تحت فرضیه تهی r* = 0. حداقل برای همبستگی تتراکوری ، یک بیان ساده بسته برای این خطای استاندارد وجود دارد (براون ، 1977). با دانستن این مقدار ، ممکن است یک مقدار z را به عنوان: جایی که مخرج خطای استاندارد R* است که در آن r* = 0. است ، با ارزیابی مقدار Z از نظر احتمالات دم مرتبط با منحنی عادی استاندارد ارزیابی کنید. واد
روش دوم از طریق تست مجذور کای است. اگر r* = 0 ، مدل همبستگی پلی چوریک همان مدل استقلال آماری است. بنابراین آزمایش فرضیه تهی r* = 0 با آزمایش مدل استقلال آماری منطقی به نظر می رسد. یا برای آزمایش مدل استقلال می توان از Pearson (x 2) یا احتمال نسبت (G 2) استفاده کرد. DF برای هر آزمایش (R - 1) (C - 1) است. یک مقدار مهم مربع chi حاکی از آن است که R* برابر با 0 نیست.
جایی که g 2H0آیا این احتمال وجود داردH1احتمال ابتلا به آن برای مدل همبستگی پلی چوریک است. تفاوت G 2 را می توان به عنوان یک مقدار کای مربع با 1 df ارزیابی کرد.- JSU ، 27 ژوئیه 00]
4- تست برابری آستانه.
برابری آستانه بین رأی دهندگان را می توان با تخمین آنچه را که می توان از آن به عنوان یک همبستگی پلیچوری محدود شده آستانه نامید ، آزمایش کرد. یعنی ، همبستگی پلی چوریک با محدودیت (های) اضافه شده تخمین می زند که آستانه (های) Rater 1 است/همان آستانه (های) Rater 2 است. تست اختلاف G 2 سپس با مقایسه آمار G 2 برای این مدل محدود با G 2 برای مدل همبستگی پلیچوری بدون محدودیت انجام می شود. تفاوت آمار G 2 به عنوان یک مقدار مجذور کای با DF = R - 1 ارزیابی می شود ، جایی که R تعداد سطح رتبه بندی است (این آزمون فقط زمانی اعمال می شود که هر دو رأی دهنده از همان تعداد رتبه بندی استفاده کنند).
پسوندها و کلیات
در اینجا ما به طور خلاصه به برخی از پسوندها و تعمیم های رویکرد همبستگی تتراکوری/پلیچوری برای تجزیه و تحلیل توافق نامه Rater توجه می کنیم:
توزیع های ناچیز. یک صفحه جدید که آنچه را که می توان به صورت محاوره ای "همبستگی تتراچوریک یا پلیچوری" نامید ، توصیف می کند ، اما با دقت بیشتری به عنوان همبستگی نهفته با یک توزیع نهفته ناچیز خوانده می شود. این صفحه همچنین یک برنامه رایانه ای ساده را برای اجرای مدل برای رتبه بندی باینری توصیف می کند.
مثال ها
مثال 1. همبستگی تتراکوری
جدول 1 رتبه بندی های فرضی توسط دو رأی دهنده در مورد حضور (+) یا غیبت (-) اسکیزوفرنی را خلاصه می کند. برای این داده ها ، همبستگی تتراکوری (خطای std.): که بسیار بزرگتر از همبستگی پیرسون 0. 4082 است که برای همان داده ها محاسبه می شود.
آستانه (خطاهای std.) برای دو رأی دهنده به این صورت تخمین زده می شود:
مثال 2. همبستگی پلیچوری
در جدول 2 تعداد بره های متولد شده در 227 میش در طی دو سال خلاصه شده است. این داده ها قبلاً توسط تالیس (1962) و دراسو (1988) مورد تجزیه و تحلیل قرار گرفتند.
تالیس اظهار داشت که تعداد بره های متولد شده ، تجلی باروری میش است-یک متغیر مداوم و بالقوه که به طور عادی توزیع می شود. واضح است که وضعیت پیچیده تر از فرضیات ساده "متغیر عادی مداوم به علاوه آستانه های گسسته کننده" است. ما داده ها را صرفاً به خاطر یک مثال محاسباتی در نظر می گیریم.
Drasgow (1988 ؛ همچنین به Olsson ، 1979 مراجعه کنید) دو روش مختلف برای محاسبه همبستگی پلی چوریک را شرح داد. روش اول ، رویکرد حداکثر احتمال مشترک (ML) ، تمام پارامترهای مدل-یعنی. ، Rho و آستانه ها را در همان زمان تخمین می زند.
روش دوم ، برآورد ML دو مرحله ای ، اول آستانه های فرکانس های حاشیه ای یک طرفه را تخمین می زند ، سپس RHO ، مشروط بر این آستانه ها را از طریق حداکثر احتمال تخمین می زند. برای همبستگی تتراکوری ، هر دو روش نتایج یکسانی را به دست می آورند. برای همبستگی پلیچوری ، آنها ممکن است نتایج کمی متفاوت داشته باشند.
داده های جدول 2 با برنامه Polycorr مورد تجزیه و تحلیل قرار می گیرد (Uebersax ، 2000). استفاده از رویکرد ML مشترک تخمین های زیر را تولید می کند (خطاهای استاندارد): با تخمین دو مرحله ای نتایج عبارتند از: با این حال مدل تست آماری G 2 برای تخمین های مشترک ML و دو مرحله ای به ترتیب 11. 54 و 11. 55 است ، هر کدام با هر یک3 dfمقادیر P مربوطه ، کمتر از 0. 01 ، نشان دهنده تناسب مدل ضعیف و غیرقابل تحمل فرضیات مدل چندوریک است. ممکن است با در نظر گرفتن توزیع صفت نهفته ، تناسب قابل قبول را بدست آورد.
مثال 3. همبستگی پلیچوری با فرضیات توزیع آرام
داده های جدول 3 ، که قبلاً توسط هاچینسون (2000) مورد تجزیه و تحلیل قرار گرفته بود ، رتبه بندی های مربوط به سلامت 460 درخت و درختچه ها را توسط دو رأی دهنده خلاصه می کند. سطح رتبه بندی حاکی از افزایش سطح سلامت گیاهان است. یعنی 1 نشان دهنده پایین ترین سطح و 6 بالاترین سطح است.
همبستگی پلیچوری (خطای std) برای این داده ها با استفاده از تخمین مشترک 954 است. با این وجود دلیلی برای تردید در فرضیات مدل همبستگی پلیچوری استاندارد وجود دارد. آمار مناسب مدل G 2 در 24 DF 57. 33 است (آمار P 2 در 19 DF 15. 65 بود (P = 0. 660). برنامه LLCA همبستگی هر متغیر را با ویژگی نهفته به عنوان 963 داد.، تخمین می زند که اگر آنها رتبه بندی خود را در مقیاس مداوم انجام دهند ، همبستگی رأی دهندگان چه خواهد بود. این یک تعمیم همبستگی پلی چوریک است ، اگرچه شاید ما باید این اصطلاح را برای مورد عادی دو متغیره نهفته رزرو کنیم. همبستگی نهفته بین رأی دهندگان.
(برای دیدن پرونده ورودی برای برنامه LLCA ، اینجا را کلیک کنید.)
توزیع صفت نهفته تخمین زده شده توسط مدل به شرح زیر است:
شکل نشان می دهد که ویژگی نهفته می تواند از نظر اقتصادی با توزیع پارامتری نامتقارن مانند یک بتا یا توزیع نمایی مدل شود.
تجزیه و تحلیل عاملی و SEM
یک صفحه وب جدید و جداگانه در مورد موضوع تجزیه و تحلیل عاملی و SEM با همبستگی های تتراکوریک و پلیچوری اضافه شده است.
نرم افزار
برنامه هایی برای همبستگی تتراکوری
TCORR یک ابزار ساده برای تخمین ضریب همبستگی تتراکوری و خطای استاندارد آن است. فقط فرکانس های یک جدول چهار برابر را وارد کرده و جواب را دریافت کنید. همچنین تخمین های آستانه را تأمین می کند.
Dirk Enzmann یک ماکرو SPSS را برای برآورد ماتریس همبستگی تتراکوری نوشت. او همچنین یک نسخه مستقل دارد.
جیم فلمینگ همچنین برنامه ای برای تخمین ماتریس همبستگی تتراکوری و اختیاری صاف از یک ماتریس با شرط نامناسب دارد.
الگوریتم براون (1977) به عنوان 116 ، یک زیرروال Fortran برای محاسبه همبستگی تتراکوریک و خطای استاندارد آن ، را می توان در Statlib یافت. از طرف دیگر ، می توانید برنامه من ، TCORR را در بالا بارگیری کنید ، که شامل کد منبع ساده با نسخه واقعی کار از زیرروه براون است.
برنامه هایی برای همبستگی چندوریک و تتراکوری
توجه داشته باشید. در حال حاضر نسخه اصلی روی سیستم عامل های ویندوز 64 بیتی اجرا نمی شود. این مورد بعداً در سپتامبر 2015 مورد بررسی قرار می گیرد.
SAS یک ضریب همبستگی چند پلی یا تتراکوری را می توان با گزینه PLCORR SAS Proc Freq محاسبه کرد. مثال:
تخمین مشترک استفاده می شود. خطای استاندارد تأمین می شود ، اما آستانه نیست. هیچ آزمایش خوبی انجام نمی شود.
از نسخه SAS� نسخه 9. 3 و SAS/STAT نسخه 13. 1 دو نفر وجود داردجدید راه هابرای محاسبه ضرایب همبستگی پلی چوریک/تتراکوری: با یک گزینه پلی چوریک جدید در Proc Corr ، و با Proc IRT. با توجه به بیش از دو متغیر ، هر دو روش می توانند ماتریس ضرایب همبستگی تتراکوری/پلی چوریک را تأمین کنند. Proc Corr (در صورت درخواست) نتایج را در لیست داده های خروجی که به راحتی برای تولید ماتریس دستکاری می شود ، می نویسد. Proc IRT به طور مستقیم خروجی ماتریس را تأمین می کند ، اما برخلاف Proc Corr ، اطلاعات مربوط به مدل مناسب برای همبستگی های فردی را ارائه نمی دهد.
کد زیر از Proc Corr برای تخمین ضریب همبستگی پلی چوریک برای داده های بره و میش در جدول 2 بالا استفاده می کند.
داده های یک ؛ورودی x1 x2 f ؛datalines ؛0 0 58 0 1 52 0 2 1 1 0 26 1 1 58 1 2 3 2 0 8 2 1 12 2 2 9 ؛
داده های دو ؛یکی را تنظیم کنیدآیا من = 1 تا f ؛خروجیپایان؛Drop I f ؛اجرا کن؛
proc corr data = دو پلی چوریک ؛var x1 x2 ؛* اختیاری: ذخیره نتایج در مجموعه داده به نام PC ؛ODS خروجی Polychoriccorr = PC ؛اجرا کن؛
Proc Corr ضرایب همبستگی تتراکوری/پلیچوری ، خطاهای استاندارد و دو آزمایش از اهمیت آماری را تأمین می کند (به عنوان مثال ، این که این همبستگی با 0 متفاوت است). برای آزمایش خوب بودن تناسب (فقط برای یک ضریب همبستگی چندگانه) می توان از Proc IRT استفاده کرد:
proc irt data = دو پیوند = polychoric probit ؛مدل X1-X2 / RESFUNC = درجه بندی ؛برابری x1-x2 / parm = [شیب] ؛اجرا کن؛
نسبت احتمال و آمار مربع کای پیرسون و DF در بخش آمار مناسب از خروجی گزارش شده است. مجدداً ، این تنها برای یک ضریب همبستگی پلی چوریک کار می کند (مدل مناسب برای ضرایب همبستگی تتراکوری غیرقابل تحمل است). می توان از PROC IRT برای برآورد ماتریس ضرایب همبستگی تتراکوریک/پلی چوریک استفاده کرد ، اما در این حالت آمار مناسب مدل تعبیر کمی متفاوت دارد.
برای کسانی که نسخه SAS قدیمی تر دارند ، یک ماکرو SAS ، ٪ Polychor ، می تواند یک ماتریس از همبستگی های پلی چوریک یا تتراکوری ایجاد کند. ماکرو نسبتاً کند است.
برای همبستگی های تتراکوری ، اگر یک فرکانس 0 در جدول کلاس 2 × 2 برای یک جفت متغیر وجود داشته باشد (شکل 3 را در بالا ببینید) ، گزینه PLCORR PROC FREQ و ٪ Polychor ممکن است به طور غیر ضروری یک نتیجه مقدار گمشده را ارائه دهد ، حداقل اگر اگر حداقل در صورتی باشد. Maxiter در مقدار پیش فرض 20 باقی مانده است. تاکنون من متوجه شده ام که با تنظیم Maxiter بالاتر ، به عنوان مثال ، به 40 ، 50 یا 100 ، این مشکل از این مشکل جلوگیری می شود.
SPSS SPSS هیچ روش ذاتی برای برآورد همبستگی های پلی چوریک ندارد. همانطور که در بالا ذکر شد ، دیرک انزمان یک ماکرو SPSS را برای برآورد ماتریس همبستگی تتراکوری نوشت.
prelisیک برنامه مفید برای برآورد ماتریس از همبستگی های پلی چوریک یا تتراکوری Prelis است. این شامل یک تست مناسب برای هر جفت متغیر است. خطاهای استاندارد قابل درخواست است. Prelis از تخمین دو مرحله ای استفاده می کند. از آنجا که با LISREL تهیه می شود ، Prelis به طور گسترده ای در دسترس است. اکثر مراکز محاسبه دانشگاه احتمالاً قبلاً دارای نسخه و/یا مجوز سایت هستند.
MPLUS می تواند یک ماتریس از همبستگی های چندوریک و تتراکوری را تخمین زده و خطاهای استاندارد آنها را تخمین بزند. تخمین دو مرحله ای استفاده می شود. ویژگی های مشابه Prelis/Lisrel.
عملکرد داخلی Stata Stata برای همبستگی های تتراکوری یک استبسیارتقریب خشن (به عنوان مثال ، همبستگی تتراکوری واقعی = . 5172 ، گزارش Stata . 6169!) بر اساس ادواردز و ادواردز (1984) و برای بسیاری یا بیشتر برنامه ها نامناسب است. یک ماژول خارجی دقیق تر توسط Stas Kolenikov برای برآورد ماتریس همبستگی های پلی چوریک یا تتراکوری و خطاهای استاندارد آنها نوشته شده است.
محاسبه ضریب همبستگی تتراکوریک/پلیچوری در r
نحوه محاسبه ضریب همبستگی پلی چوریک با استفاده از r
1. R را از وب سایت Cran (رایگان) بارگیری کنید و روی رایانه خود نصب کنید: http://cran. r-project. org/
2. بارگیری و نصب RSTUDIO (رایگان): https // www.rstudio.com
4. At command prompt (">") نوع: install. packages (" polycor ")
5. پس از اتمام این عمل ، نوع: کتابخانه ("PolyCor")
6. فرکانس های تهیه یک جدول طبقه بندی دو طرفه به عنوان یک بردار ، به عنوان مثال ،
همبستگی پلیچوری X ، Ml Est. = -0. 1183 (0. 06098) تست عادی دو متغیره: Chisquare = 1. 216 ، DF = 3 ، P = 0. 7491
آستانه آستانه ردیف std. err. 1-0. 6227 0. 06345 2 0. 2535 0. 05976
آستانه آستانه ستون std. err. 1-1. 11100 0. 07450 2-0. 08275 0. 05914
مقدار تخمین زده شده از ضریب همبستگی پلی چوری ک-0. 1183 با خطای استاندارد تخمین زده شده 0. 06098 است.
اگر X تنها دو سطح (ردیف و ستون) داشته باشد ، همبستگی تتراکوری تخمین زده می شود.
همچنین می توان داده های خام را به صورت دو بردار X و Y تهیه کرد. به عنوان مثال ، بگذارید x = c (1 ، 2 ، 1 ، 1 ، 2 ، 1 ، 1 ، 1 ، 2 ، 1) ، y = c (2 ، 1 ، 2 ، 2 ، 1 ، 1 ، 1 ، 2 ، 1، 2). توجه داشته باشید که این دو متغیر است که در همان افراد/اشیاء اندازه گیری می شوند ، بنابراین طول و ترتیب آنها باید مطابقت داشته باشد.
همبستگی پلیچوری X ، ML Est. = 0. 3672 (0. 3574)
آستانه آستانه ردیف std. err. 0. 1573 0. 3147
آستانه آستانه ستون std. err. 0. 1573 0. 3147
همچنین به توابع مربوط به ضرایب همبستگی پلیچوریک و پلیسری در کتابخانه روانی ویلیام Revelle در شمال غربی مراجعه کنید.
همبستگی نهفته تعمیم یافته
در هر صورت، مقالات متعددی بر اساس تسهیل این فرض، الحاقات را بررسی کرده اند. توزیع های غیر گاوسی، مخلوطی از توزیع ها و توزیع های گاوسی اریب همگی در نظر گرفته شده اند (اکسترم، 2011؛ کوتاس، مولر و کوینتانا، 2005؛ کویروگا، 1992؛ روسینو و پولیس، 2006؛ تیموفیوا و خایلن 2016).
رویکردی که من در چندین مقاله اتخاذ کرده ام، مسئله را به عنوان یک مدل صفت نهفته یک بعدی مجدداً پارامترسازی می کند. اگر صفت نهفته توزیع گاوسی داشته باشد، نتایج تولید شده با نتایج ضریب همبستگی پلی کوریک معمولی یکسان است. با این حال، توزیع های دیگری از صفت پنهان را می توان فرض کرد - مانند توزیع های اریب، مخلوطی از توزیع های گاوسی (Uebersax & Grove, 1993) یا یک توزیع نیمه پارامتریک (Uebersax, 1993). از آنجا که ادغام تنها در یک بعد مورد نیاز است، این روش از نظر محاسباتی جذاب است. برخی از برنامه های کامپیوتری برای تخمین این مدل ها در زیر توضیح داده شده است.
برنامه glc همبستگی تتراکوریک را تعمیم می دهد تا همبستگی نهفته بین متغیرهای باینری را با فرض توزیع صفت پنهان اریب تخمین بزند.
توزیع اریب به عنوان مخلوطی از دو توزیع گاوسی مدل سازی می شود که کاربر پارامترهای آن را ارائه می کند. یعنی از قبل شکل توزیع صفت پنهان را بر اساس باورها/دانش قبلی مشخص می کند. استفاده از این برنامه بسیار ساده تر از مواردی است که در زیر توضیح داده شده است. چندین مجموعه از داده ها (خلاصه شده به صورت یک سری جداول 2×2) را می توان در یک اجرا تجزیه و تحلیل کرد.
برنامه LTMA می تواند به طور مشابه برای تخمین همبستگی چند کوریک تعمیم یافته، بر اساس یک مدل مخلوط صفت نهفته استفاده شود (Uebersax & Grove، 1993). این اساساً یک نسخه جذاب تر از برنامه glc است: (1) متغیرهای مرتب و دسته بندی شده و همچنین متغیرهای دوگانه را کنترل می کند و (2) شکل توزیع صفت نهفته را از داده ها تخمین می زند (دوباره، آن را به عنوان مخلوط مدل می کند. گاوسی دو جزء).
برآورد MCMC
به دنبال آلبرت (1992)، مقالات زیادی در مورد استفاده از روش های زنجیره مارکوف مونت کارلو (MCMC) برای تخمین ضریب همبستگی چند کوریک وجود دارد. نمی توان انکار کرد که رویکرد MCMC دارای مزایای بسیاری است (مانند توانایی گنجاندن اطلاعات قبلی اطلاعاتی در تخمین)، و بدون شک تحقیقات در این زمینه امیدوارکننده ادامه خواهد داشت.(در آینده منابع بیشتری اضافه خواهد شد.)
با این حال ، در عین حال مهم است که مزایای متمایز یک رویکرد سنتی (یعنی حداکثر احتمال مستقیم) را در ذهن داشته باشید. این موارد عبارتند از: (1) نتایج دقیق تر ، (2) توانایی تست تست مدل با استفاده از آمار مربع مجذور ، (3) توانایی مقایسه مدل های تو در تو از طریق نسبت احتمال و آمار مشابه ، و (4) محاسبات سریعتر ، که از جملهچیزهای دیگر ، تخمین کل ماتریس همبستگی را تسهیل می کند.
پیوندهای مفید
منابع
آلبرت ، ج. برآورد بیزی از ضریب همبستگی پلی چوریک. مجله محاسبات و شبیه سازی ، 1992 ، 44 ، 47-61.
اسقف YMM ، Fienberg SE ، Holland PW. تجزیه و تحلیل چند متغیره گسسته: تئوری و عمل. کمبریج ، ماساچوست: MIT Press ، 1975
MB قهوه ای. الگوریتم به عنوان 116: همبستگی تتراکوری و خطای استاندارد آن. آمار کاربردی ، 1977 ، 26 ، 343-351.
همبستگی های Drasgow F. Polychoric و Polyserial. در Kotz L ، Johnson NL (Eds.) ، دائر ycl المعارف علوم آماری. جلد7 (صص 69-74). نیویورک: ویلی ، 1988.
ادواردز JH ، ادواردز AWF. تقریب ضریب همبستگی تتراکوری. بیومتریک ، 1984 ، 40 ، 563.
ضریب همبستگی هریس ب. در Kotz L ، Johnson NL (Eds.) ، دائر ycl المعارف علوم آماری. جلد9 (صص 223-225). نیویورک: ویلی ، 1988.
هاچینسون TP. کاپا دو منبع اختلاف نظر را با هم جمع می کند: همبستگی تتراکوری بهتر است. تحقیقات در پرستاری و بهداشت ، 1993 ، 16 ، 313-315.
هاچینسون TP. ارزیابی سلامت گیاهان: شبیه سازی به ما کمک می کند تا اختلافات ناظر را درک کنیم. محیط زیست ، 2000 ، 11 ، 305-314.
Joreskog KG ، Sorbom ، D. Prelis کتابچه راهنمای کاربر ، نسخه 2. شیکاگو: نرم افزار علمی ، شرکت ، 1996.
Knol DL ، ده برژ JMF. حداقل مربعات تقریب یک ماتریس همبستگی نادرست توسط یک مناسب. Psychometrika ، 1989 ، 54 ، 53-61.
Kottas A ، M�ller P ، Quintana F. مدل سازی بیزی غیر پارامتری برای داده های مرتبه چند متغیره. مجله آمار محاسباتی و گرافیکی 2005 ، 14. 3 ، 610-625.
Loehlin JC. مدل های متغیر نهفته ، چاپ 3. لارنس ارلباوم ، 1999.
OLSSON U. برآورد حداکثر احتمال ضریب همبستگی پلی چوریک. Psychometrika ، 1979 ، 44 (4) ، 443-460.
Quiroga Am. مطالعات مربوط به همبستگی پلی چوریک و سایر اقدامات همبستگی برای متغیرهای منظم. دکتریپایان نامه ، دانشگاه اوپسالا ، 1992.
Roscino A ، Pollice ، A. تعمیم ضریب همبستگی پلی چوریک. تجزیه و تحلیل داده ها ، طبقه بندی و جستجوی رو به جلو. اسپرینگر ، برلین ، هایدلبرگ ، 2006. (صص 135-142).
تالیس جنرال موتورز. حداکثر برآورد احتمال همبستگی از جداول احتمالی. بیومتریک ، 1962 ، 342-353.
Timofeeva ay ، Khailenko ، EA. تعمیم رویکرد همبستگی پلی چوریک برای تجزیه و تحلیل داده های نظرسنجی. فناوری استراتژیک (IFOST) ، یازدهمین مجمع بین المللی 2016. IEEE ، 2016.
Uebersax JS. LLCA: تجزیه و تحلیل کلاس نهان واقع شده است. مستندات برنامه رایانه ای ، 1993a.
Uebersax JS. مدل سازی آماری رتبه بندی های متخصص در مناسب بودن درمان پزشکی. مجله انجمن آماری آمریکا ، 1993b ، 88 ، 421-427.
Uebersax JS. Polycorr: برنامه ای برای تخمین ضریب همبستگی پلیچوری استاندارد و گسترده. مستندات برنامه رایانه ای ، 2000.
آخرین به روزرسانی: 5 اکتبر 2018 (کد SAS PROC IRT اضافه شده است) (ج) 2010 2018 ایمیل دکتری جان Uebersax
-
- df = rc - r - c
- g 2H0- g 2H1,
- Tetmat برنامه رایگان من برای برآورد ماتریس همبستگی تتراکوری است. همچنین اطلاعات مفید دیگری مانند فرکانس ها و نرخ های حاشیه ای یک و دو طرفه ، خطاهای استاندارد بدون علامت RHO ، مقادیر P ، دامنه اعتماد به نفس و آستانه را ارائه می دهد. مقرراتی برای صاف کردن یک ماتریس همبستگی بالقوه نادرست با روش Knol و Ten Berge (1989) انجام شده است.
- نسخه اساسیاین فقط جداول مربع را کنترل می کند (یعنی مدل هایی که هر دو مورد دارای تعداد یکسان هستند).
- جان فاکس با عملکردی برای تخمین همبستگی پلی چوریک (و تتراچوریک) ، یک کتابخانه R ، Polycor کمک کرده است.
- یک محدودیت بالقوه آشکار از ضریب همبستگی پلی چوریک فرض بر این است که متغیرهای نهفته دارای توزیع گاوسی دو متغیره هستند. Ekstr�m (2011) گزارش می دهد که پیرسون از این امر کمی زحمت کشیده است ، بدیهی است که معتقد است که همبستگی چندوریک می تواند به طور مؤثر مورد استفاده قرار گیرد حتی اگر فرضیات توزیع به شدت برآورده نشوند.
- "همبستگی پلیچوری" - ویکی پدیا
- صفحه همبستگی (Statnotes) - توسط G. David Garson

ما را در سایت تجارت با گزینههای باینری دنبال می کنید
برچسب :
نویسنده : حمیدرضا پگاه
بازدید : 31
